When is aggregated DEUP reliable?
DEUP's g(x) is reliable at the individual level across domains. But people
routinely aggregate it into a context-level signal — "how risky is today's
cross-section?", "is this batch out-of-distribution?" — by taking
\(\text{agg\_g}(c) = \frac{1}{N_c}\sum_{i \in c} g(x_i)\). That aggregate is only
trustworthy under specific conditions, and silently exposing
context_uncertainty = mean(g) without a guard is a trap.
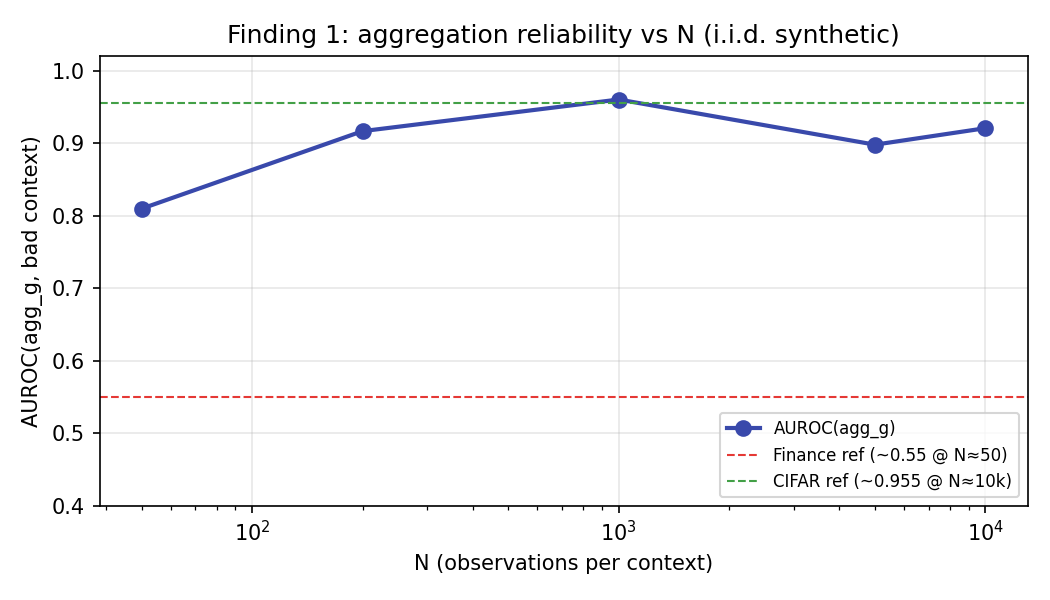
The aggregation N / i.i.d. law (Finding 1; Sanderink, 2026)
mean(g) over a context is a consistent estimator of the mean context error — but
only as \(N \to \text{large}\) and only if the within-context errors are
exchangeable (i.i.d.). With small \(N\) and temporal-regime dependence, the estimator's
variance and bias swamp the signal (Sanderink, 2026, Finding 1).
Documented empirical reference points from Sanderink (2026) (orientation, not a promise for your data):
| Regime | N per context | i.i.d.? | AUROC(agg_g, bad context) |
|---|---|---|---|
| Vision batches (CIFAR-10-C) | ~10,000 | yes | 0.955 |
| Finance cross-sections | ~50 | no (regime) | 0.55 |
So the operational rule of thumb is roughly AUROC ≈ 0.55 at N ≈ 50, ≈ 0.955 at N ≈ 10,000.
The guard: AggregationReliability
Rather than trusting raw \(N\), the diagnostic estimates an effective sample size that discounts \(N\) by within-context lag-1 autocorrelation (\(N_\text{eff} = N\frac{1-\rho}{1+\rho}\)), and warns when aggregation is unlikely to be trustworthy.
from deup.diagnostics import should_trust_aggregate
verdict = should_trust_aggregate(g, groups) # g per item, groups = context label
print(verdict.trustworthy, verdict.reason)
# False, "aggregate NOT trustworthy (median N_eff=21 < 200; ...); prefer a composite HealthIndex"
Or aggregate with the guard built in (emits a UserWarning when untrustworthy):
from deup.diagnostics import AggregationReliability
labels, mean_g, verdict = AggregationReliability().aggregate(g, groups)
The remedy for low-N / non-i.i.d.: HealthIndex (Finding 2; Sanderink, 2026)
When aggregated raw g fails, a composite health index that fuses
complementary signals recovers context-level detection (Sanderink, 2026, Finding 2):
Empirically this lifts context-level detection well above raw agg_g in the finance
regime. The index is general (not finance-only): supply any list of pluggable
component callables, each returning one scalar per context where higher = worse.
from deup.diagnostics import (
HealthIndex, realized_efficacy, drift_psi, model_disagreement,
)
health = HealthIndex(components=[
("realized_efficacy", realized_efficacy),
("drift_psi", drift_psi),
("model_disagreement", model_disagreement),
])
report = health.compute(
groups,
{
"loss": realized_loss, # per item
"feature": drift_feature, # per item
"feature_reference": baseline, # 1-D reference sample
"disagreement": ens_disagree, # per item
},
)
report.health # per-context health in [0, 1], higher = healthier
report.gate # bool per context: True = trust / trade
report.verdict(label) # gate decision for one context
Components are z-scored across contexts (so heterogeneous scales combine), weighted-
summed into a "badness" score, then mapped to a health score in \([0, 1]\) with a gating
threshold. Keep it off the high-N i.i.d. default path — there, individual-level g
already saturates and the composite is unnecessary.
Empirical N-sweep (benchmark)
The N-sweep benchmark reproduces Finding 1 (Sanderink, 2026) on controlled synthetic data: AUROC(agg_g) rises to ≈0.96 at high N (i.i.d.), while low-N autocorrelated contexts stay near-chance and HealthIndex recovers detection.
Reference
Sanderink, U. (2026) 'When Alpha Breaks: Two-Level Uncertainty for Safe Deployment of Cross-Sectional Stock Rankers', arXiv preprint arXiv:2603.13252. Available at: https://arxiv.org/pdf/2603.13252.
The core DEUP method remains Lahlou et al. (2023).